[October 18th 2025 update - replacing arcived {RSocrata} with {socratadata}]
Open Data of Baby Names
Open Data Buffalo is a great resource and initiative to make datasets open and available to the public.
My partner works at a Children’s hospital and is convinced of trending baby names. Well, I said to her let’s see what the data says!
So I ventured out into the world wide web and found a dataset called:
Baby Names: Beginning 2007
New York State (NYS) Baby Names are aggregated and displayed by the year, county, or borough where the mother resided as stated on a New York State or New York City (NYC) birth certificate. The frequency of the baby name is listed if there are 5 or more of the same baby name in a county outside of NYC or 10 or more of the same baby name in a NYC borough.
This dataset is already tidy: One row per observation (first_name or baby name) and one column per variable (e.g. the number of observed names in a county with the given gender on the birth certificate).
I first check a few data quality characteristics such as missingness and number of unique things in each column:
purrr::map_dfr(baby_names,~{sum(is.na(.x))})
# A tibble: 1 × 5
year first_name county sex name_count
<int> <int> <int> <int> <int>
1 0 0 0 0 0
purrr::map_dfr(baby_names,~{n_distinct(.x)})
# A tibble: 1 × 5
year first_name county sex name_count
<int> <int> <int> <int> <int>
1 16 2393 61 2 244
The baby_names dataset requires initial preprocessing
Now we need to transform our dataset by first converting columns to the appropriate data types:
year first_name county sex
Min. :2007 EMMA : 582 Kings :11932 Male :52728
1st Qu.:2010 OLIVIA : 562 Suffolk : 9439 Female:46388
Median :2014 LOGAN : 536 Nassau : 8488
Mean :2014 LIAM : 535 Queens : 8038
3rd Qu.:2018 MASON : 522 Westchester: 6691
Max. :2022 NOAH : 520 Erie : 6160
(Other):95859 (Other) :48368
name_count
Min. : 5.00
1st Qu.: 6.00
Median : 11.00
Mean : 17.57
3rd Qu.: 19.00
Max. :297.00
After the data transformation, we see that counties are specified in different cases. We should revise this so county (and also first_name) are in one type of case such as title case:
year first_name county sex
Min. :2007 Emma : 582 Kings :11932 Male :52728
1st Qu.:2010 Olivia : 562 Suffolk : 9439 Female:46388
Median :2014 Logan : 536 Nassau : 8488
Mean :2014 Liam : 535 Queens : 8038
3rd Qu.:2018 Mason : 522 Westchester: 6691
Max. :2022 Noah : 520 Erie : 6160
(Other):95859 (Other) :48368
name_count
Min. : 5.00
1st Qu.: 6.00
Median : 11.00
Mean : 17.57
3rd Qu.: 19.00
Max. :297.00
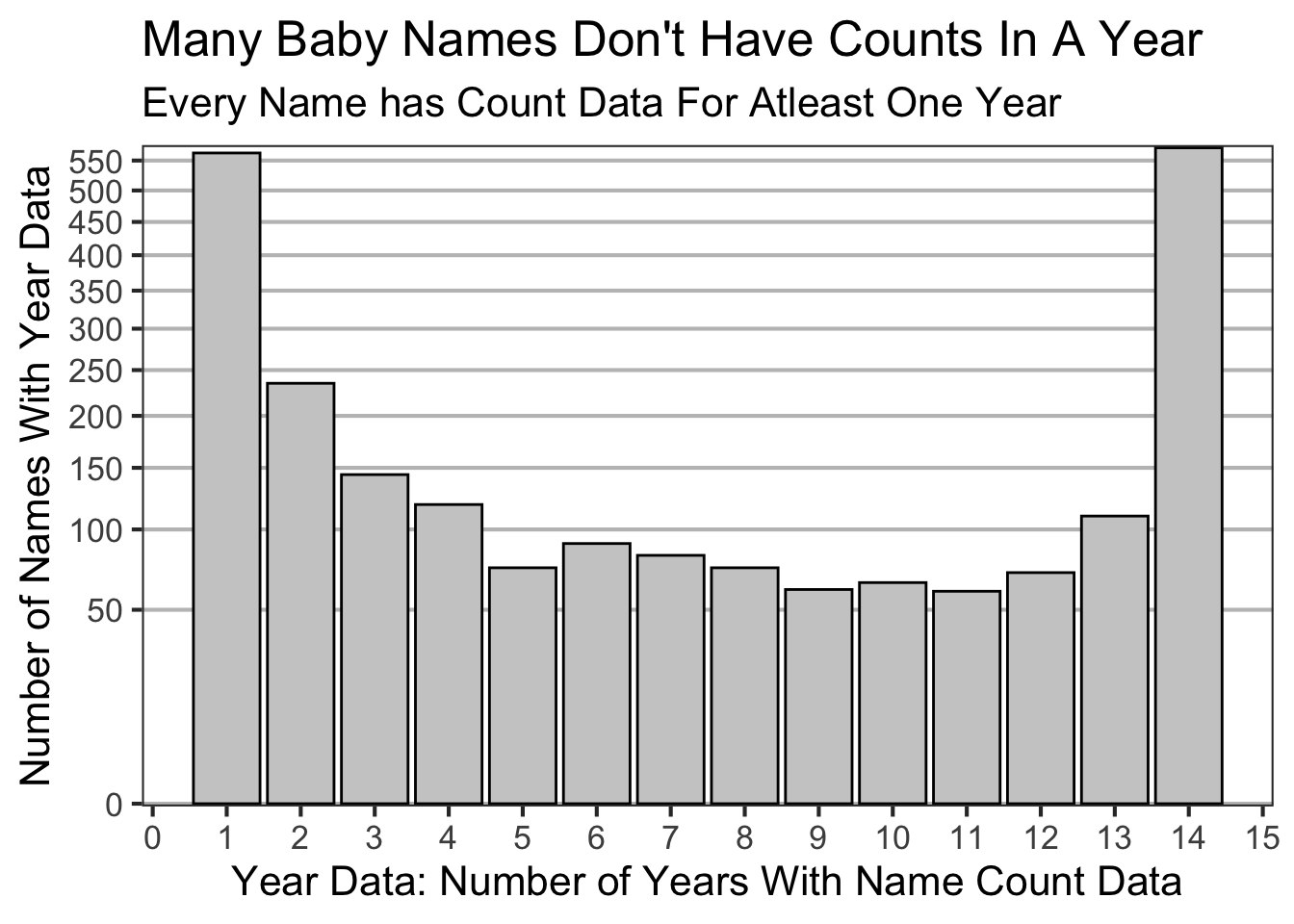
Many Baby Names Don’t Have Counts In A Year
My next data quality question is how many names have data each year?
theme_set(theme_bw(base_size =16))baby_names_transformed %>%summarize(n_years =n_distinct(year),.by=c(first_name)) %>%summarize(n_names =n_distinct(first_name),.by=n_years) %>%ggplot(aes(n_years,n_names)) +geom_bar(color="black",fill ="gray80",stat ="identity") +scale_x_continuous(breaks = scales::pretty_breaks(14)) +scale_y_continuous(expand =c(0,0.1),trans="sqrt",breaks = scales::pretty_breaks(10)) +labs(x="Year Data: Number of Years With Name Count Data",y="Number of Names With Year Data",title="Many Baby Names Don't Have Counts In A Year",subtitle="Every Name has Count Data For Atleast One Year") +theme(panel.grid.major.y =element_line(color="gray75"),panel.grid.minor.y =element_blank(),panel.grid.major.x =element_blank(),panel.grid.minor.x =element_blank() )
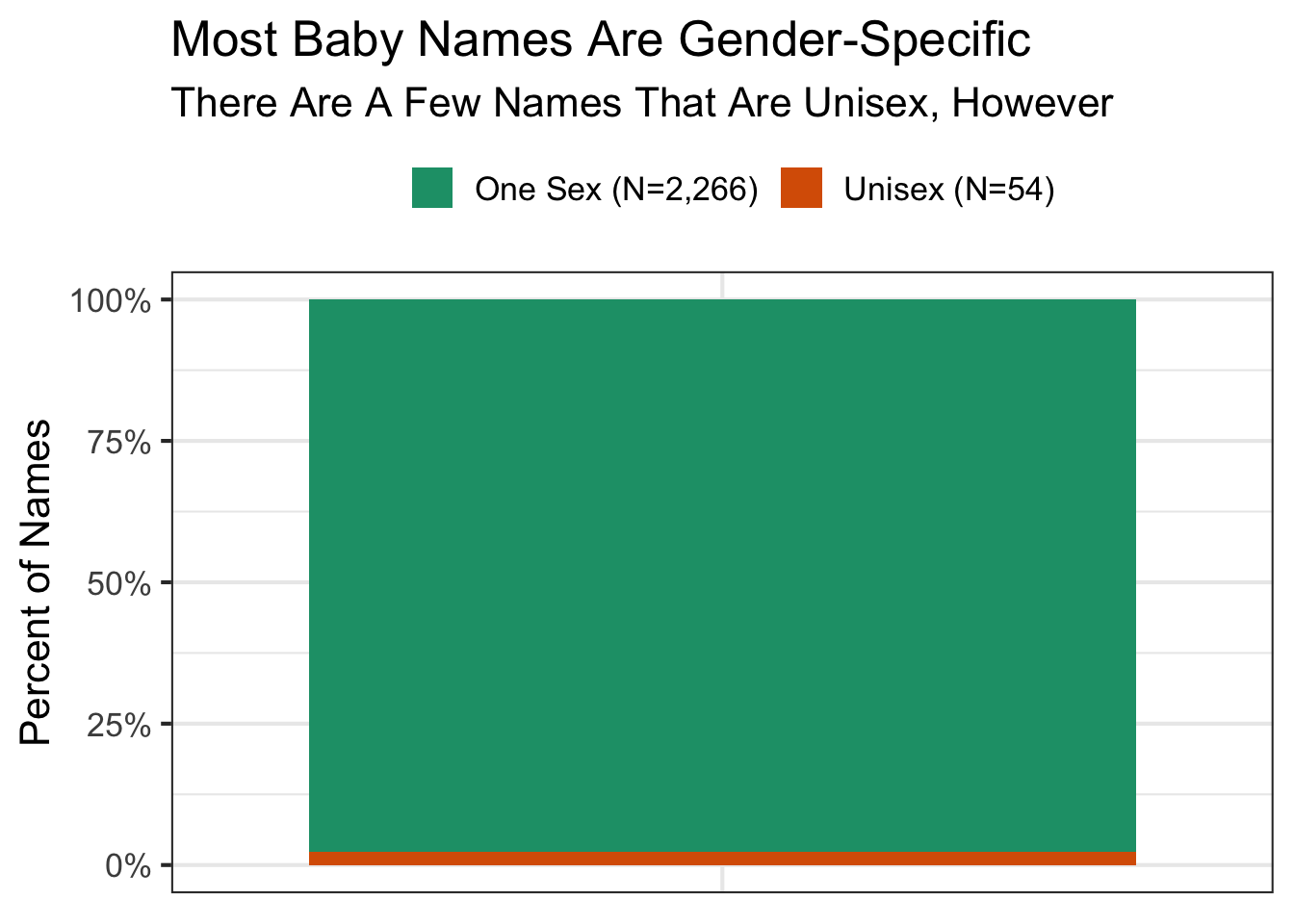
Most Baby Names Are Gender-Specific
Another question is are there many names that are unisex i.e. male and female names?
tmp <- baby_names_transformed %>%summarize(n_sex =n_distinct(sex),unisex = n_sex==2,onesex = n_sex==1,.by=c(first_name)) %>%summarize(`Unisex`=sum(unisex),`One Sex`=sum(onesex))tmp %>%pivot_longer(cols =everything()) %>%mutate(label = glue::glue("{name} (N={scales::comma(value)})")) %>%ggplot(aes(factor(1),value,fill=label)) +geom_bar(stat="identity",position ="fill") +scale_fill_brewer(palette ="Dark2") +scale_y_continuous(labels = scales::percent) +guides(fill=guide_legend(title=NULL)) +labs(x=NULL,y="Percent of Names",title="Most Baby Names Are Gender-Specific",subtitle ="There Are A Few Names That Are Unisex, However") +theme(axis.ticks.x =element_blank(),axis.text.x =element_blank(),legend.position ="top" )
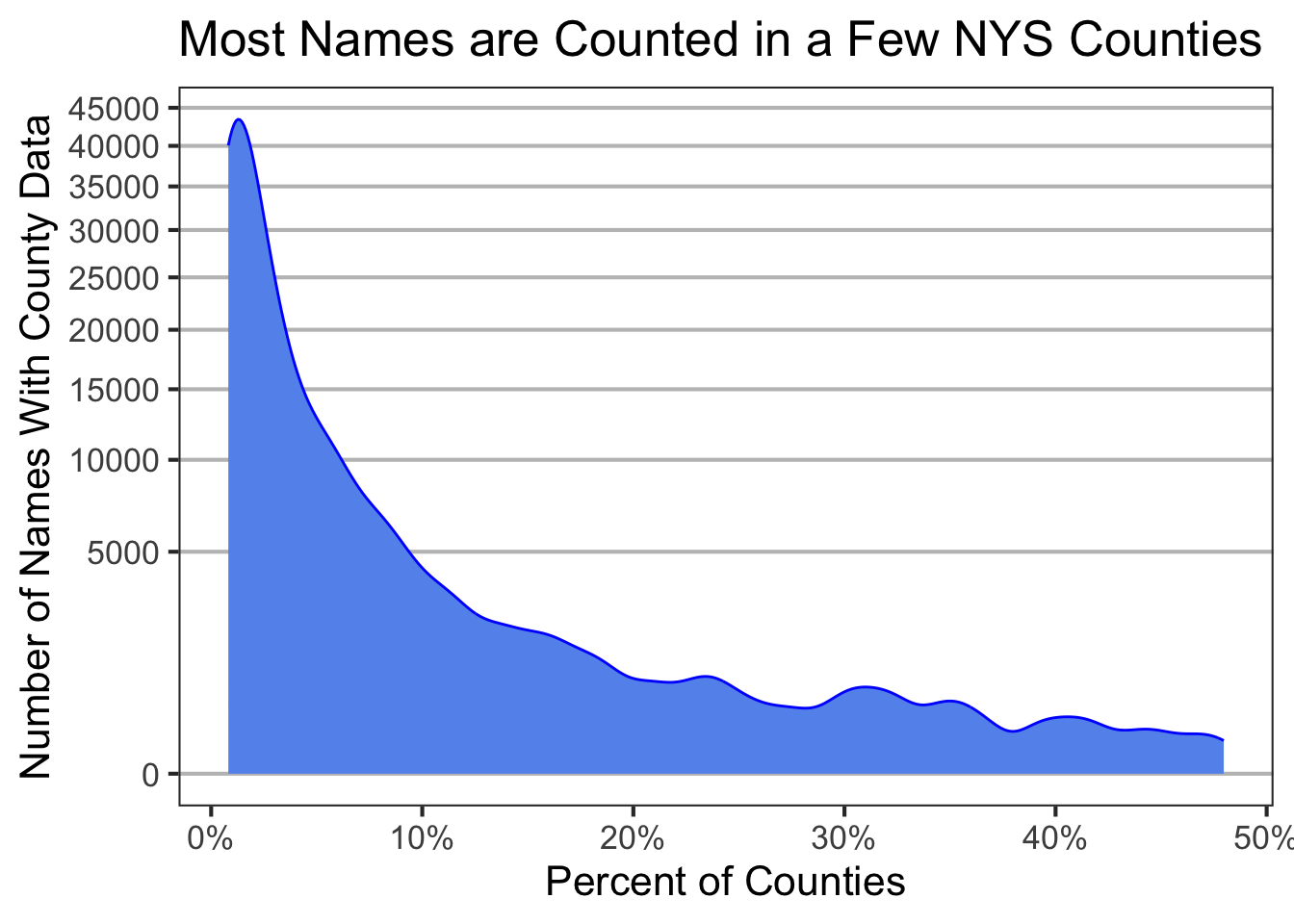
Most Baby Names are Counted in a Few NYS Counties
My last data quality question is how many baby names have data across counties?
baby_names_transformed %>%summarise(n_counties =n_distinct(county),.by=first_name) %>%bind_cols(summarise(baby_names,total_counties =n_distinct(county)) ) %>%mutate(freq_counties = n_counties / total_counties ) %>%ggplot(aes(freq_counties,y=after_stat(count))) +geom_density(bw="nrd",color="blue",fill="cornflowerblue") +scale_x_continuous(labels = scales::percent) +scale_y_sqrt(breaks = scales::pretty_breaks(15)) +labs(x="Percent of Counties",y="Number of Names With County Data",title="Most Names are Counted in a Few NYS Counties") +theme(panel.grid.major.y =element_line(color="gray75"),panel.grid.minor.y =element_blank(),panel.grid.major.x =element_blank(),panel.grid.minor.x =element_blank() )
After transforming the dataset and checking data quality, we see that:
Baby names are sparsely annotated across counties
Baby names are, generally, specific to a year or are observed across all years
There are a few baby names that are not gender-specific.
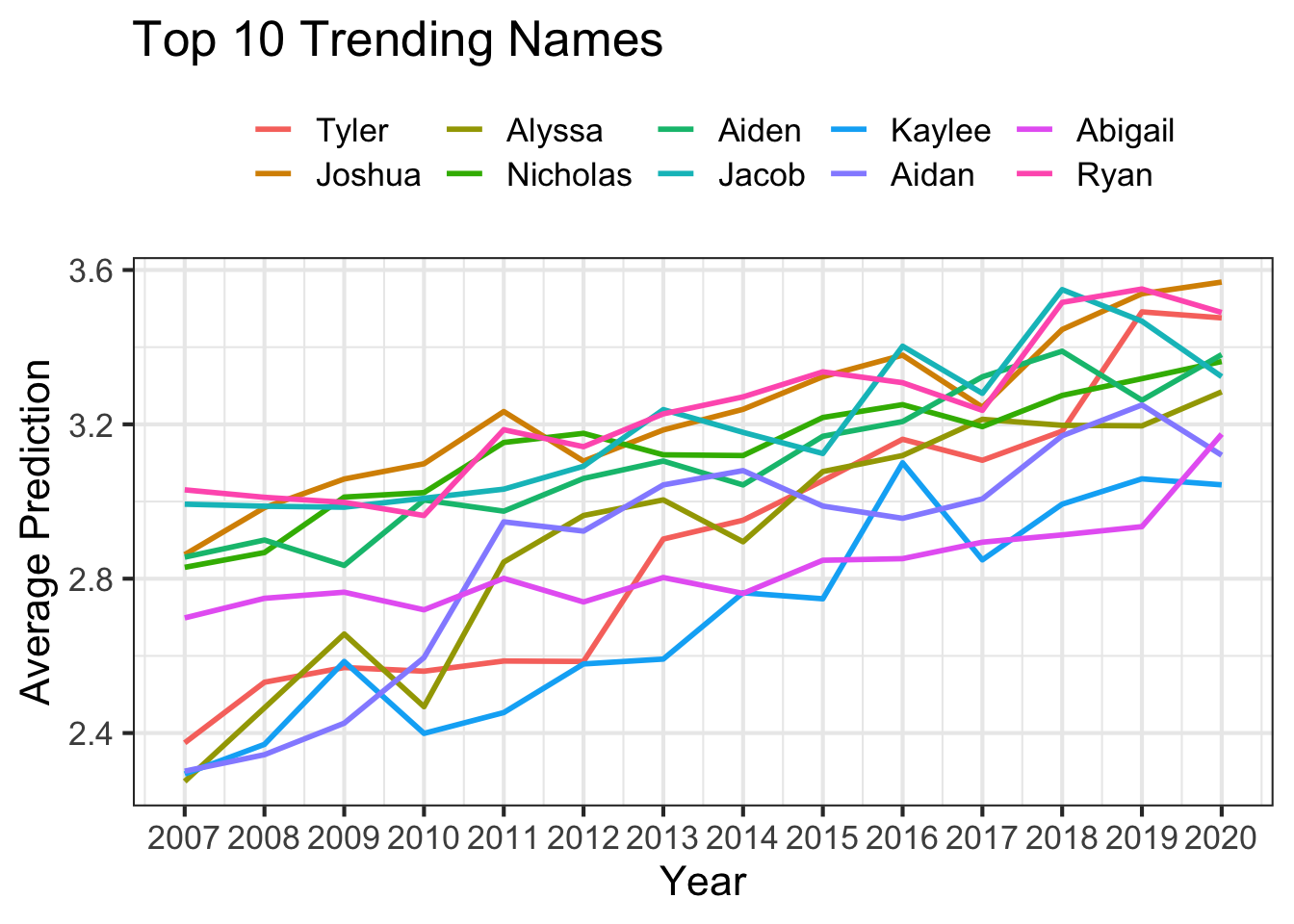
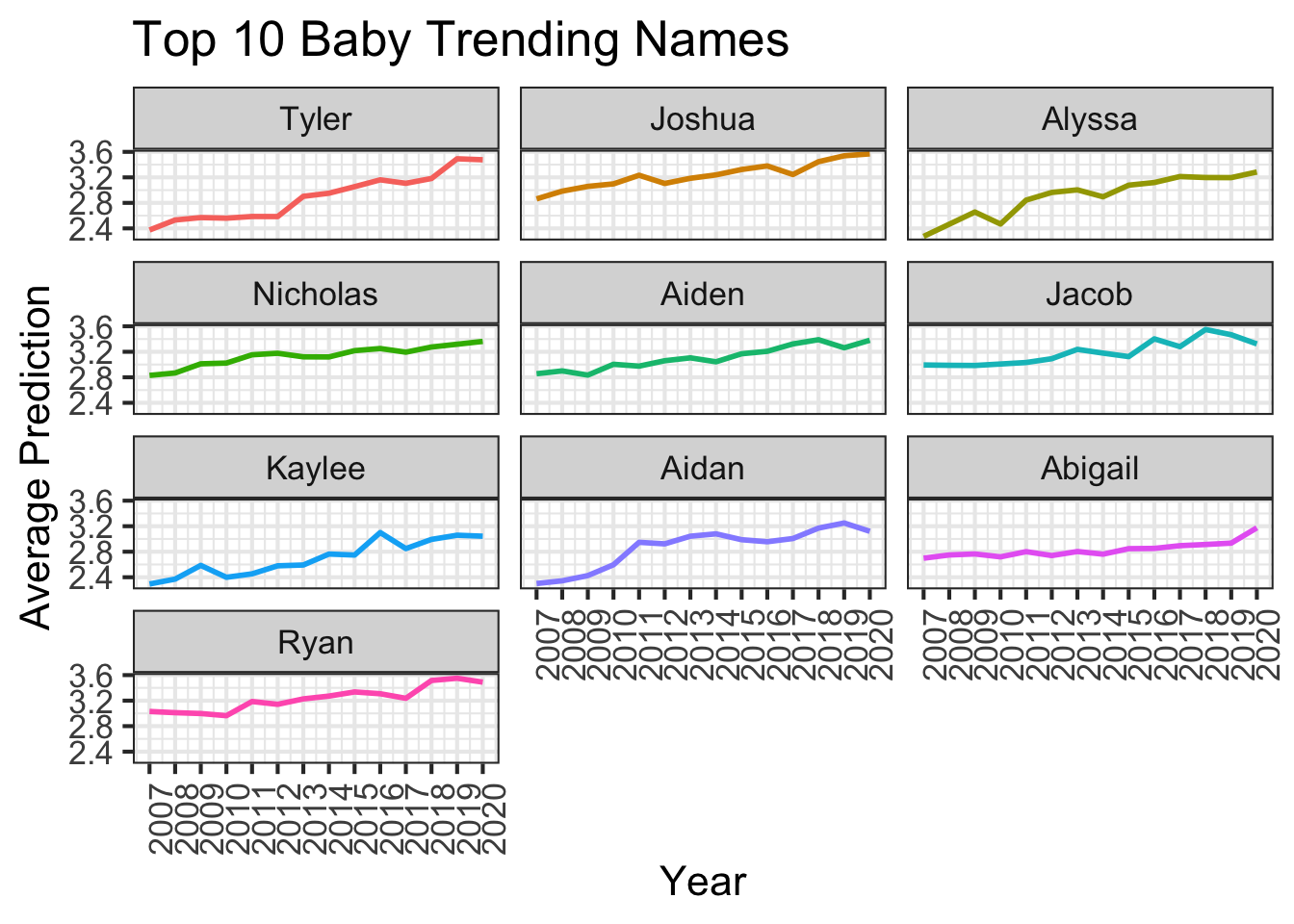
What are the trending baby names in NYS?
I want to ask the question what are the trending baby names in NYS? My question is not specific to the gender or county. Also, my question wants to consider all the baby names in the dataset as possible influencing factors in which baby names are trending. Because of the missing count data, we should use a model to estimate the trend based on the available data. The model we will use is a generalized additive model (GAM) to predict the Poisson distribution count of the baby name. *
We can estimate baby name trends using generalized additive models
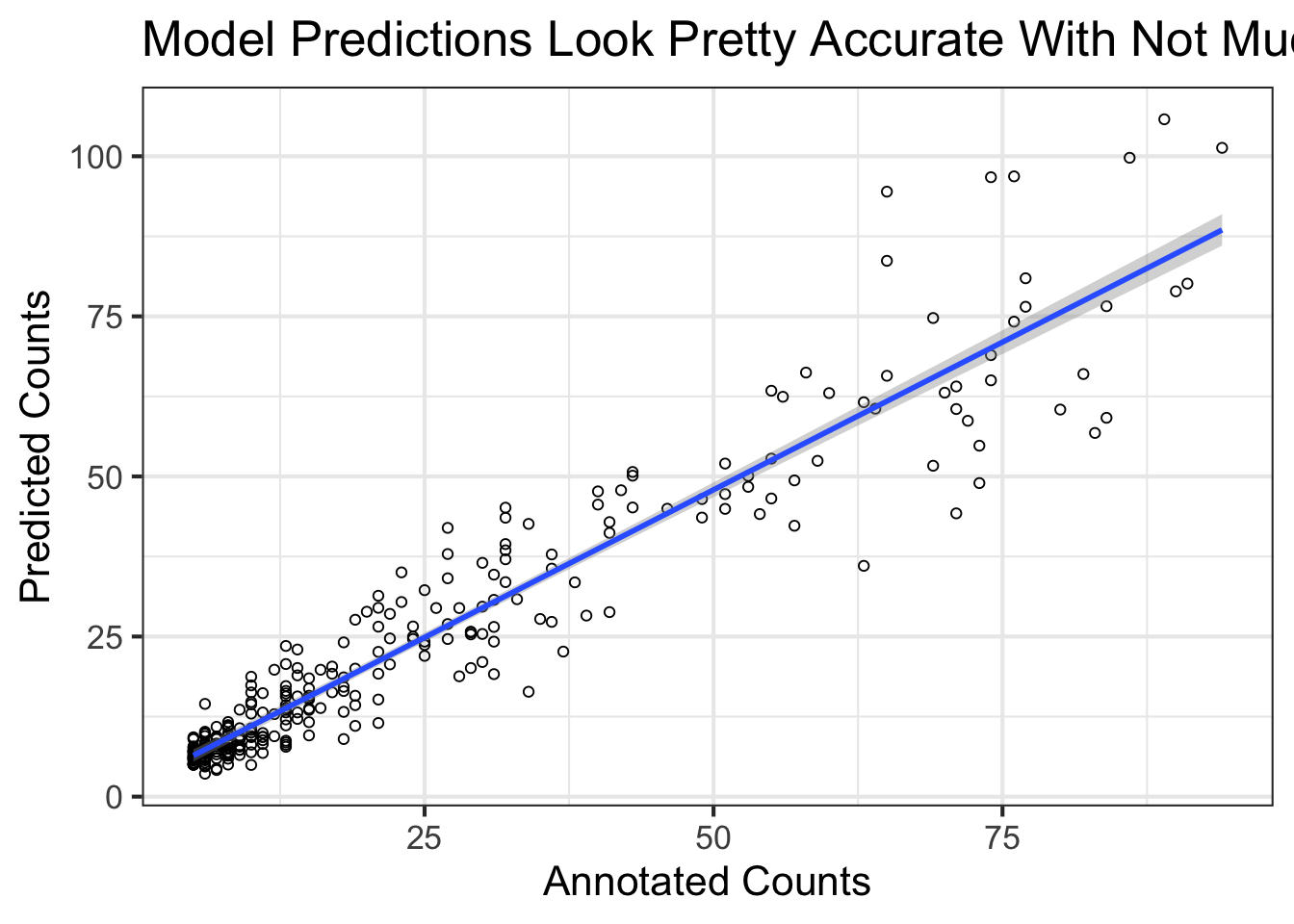
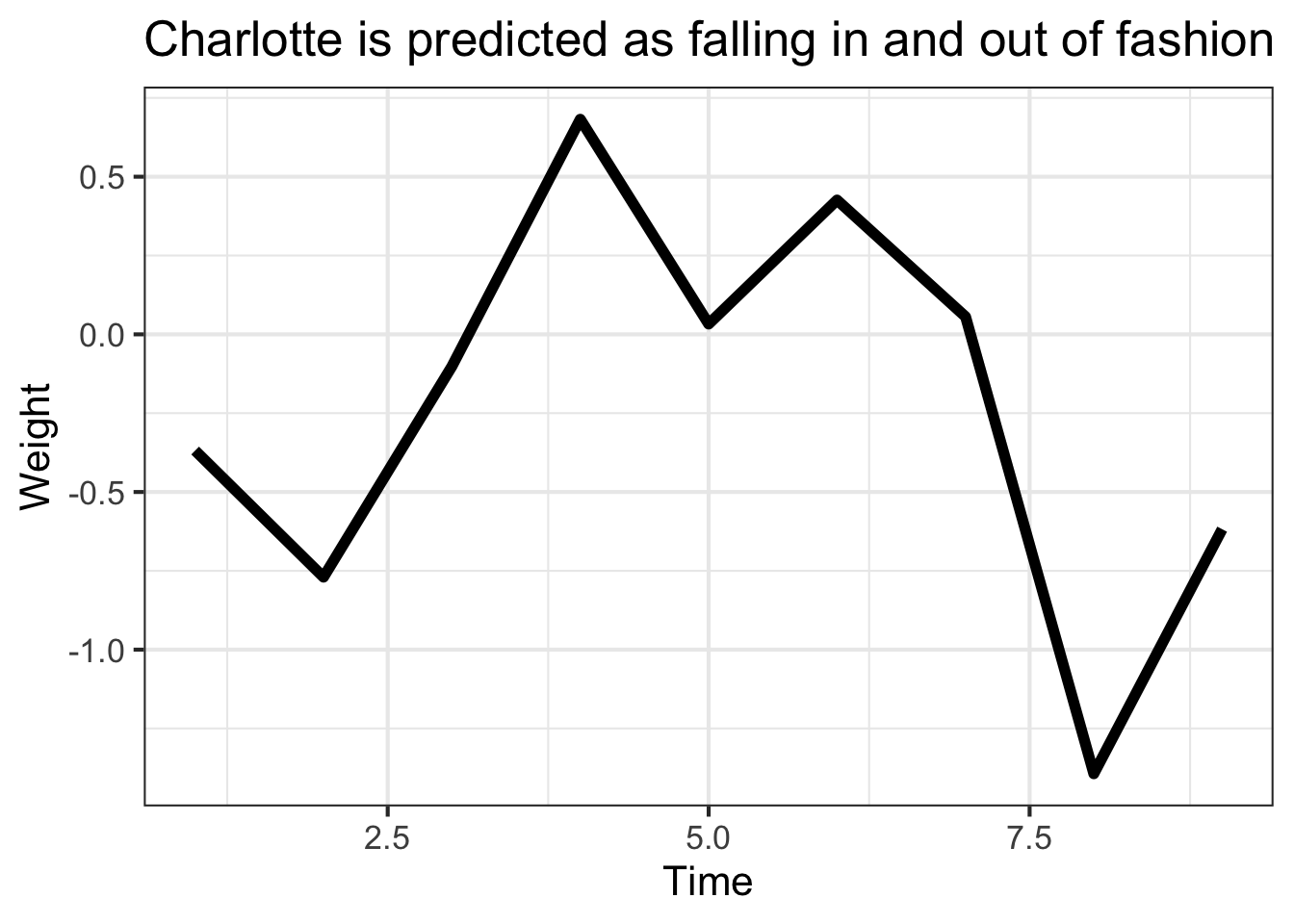
Let’s do a small example first. My subquestion is, is the baby name Charlotte trending over time irrespective of other factors?
library(mgcv)
Loading required package: nlme
Attaching package: 'nlme'
The following object is masked from 'package:dplyr':
collapse
This is mgcv 1.9-3. For overview type 'help("mgcv-package")'.
tmp <- baby_names_transformed %>%filter(first_name=="Charlotte")form <-as.formula(glue::glue("name_count ~ s(year) + county:year"))fit <- mgcv::gam(form,family="poisson",data=tmp,method ="GACV.Cp")tmp %>%bind_cols(.pred = fit$fitted.values) %>%ggplot(aes(name_count,.pred)) +geom_point(shape=21) +geom_smooth(formula ='y ~ x',method="lm") +labs(x="Annotated Counts",y="Predicted Counts",title="Model Predictions Look Pretty Accurate With Not Much Bias")
coefs_ <- fit$coefficients[str_detect(names(fit$coefficients),"s\\(year\\)")] %>%unname()tibble(year =seq_along(coefs_),coef = coefs_) %>%ggplot(aes(year,coef)) +geom_line(linewidth=2) +labs(x="Time",y="Weight",title="Charlotte is predicted as falling in and out of fashion")
GAMs allow for estimating trends given “random” naming patterns across NYS counties over time
If we want to consider all names, we need to specify the name as a random effect and the trend line as a random slope between the name and the year:
We can use this formula in our model to get the trends of the baby names over time (Note: we switch from gam to bam so that we can fit the model faster using method = ‘fREML’):